人工智能领域正迅速发展,各类模型为解决不同问题而生。本文将介绍两种重要的AI模型类型:推理模型(Reasoning Model)和多模态模型(Multimodal Model),探讨它们的原理、功能及优缺点。
推理模型专注于解决需要复杂、多步骤思考的问题。其核心在于能够展示解决问题的中间步骤和思考过程,而不仅仅是给出答案。
推理模型被定义为能够回答需要复杂、多步骤生成并包含中间步骤的问题的AI系统。与简单的事实问答不同,这类模型擅长处理需要连贯逻辑思考的任务,模拟人类解决问题的思维过程。当面对数学题、逻辑推理或复杂决策问题时,推理模型会像人类一样,逐步分解问题,展示思考或思维过程,让用户理解答案的来源和推导方式。
例如,对于一列火车以每小时60英里的速度行驶3小时,它能走多远?这样的问题,推理模型不会简单地给出180英里的答案,而是会呈现速度是60英里/小时,时间是3小时,根据距离=速度×时间,可得距离=60×3=180英里这样的完整思考过程。
推理模型的优势在于其思考过程透明,结果可解释性强,特别适合需要严谨逻辑的科学研究、教育和决策支持领域。然而,其局限也很明显,对单一类型数据的依赖可能导致缺乏全面性,且由于需要生成详细的推理步骤,处理速度可能较慢。
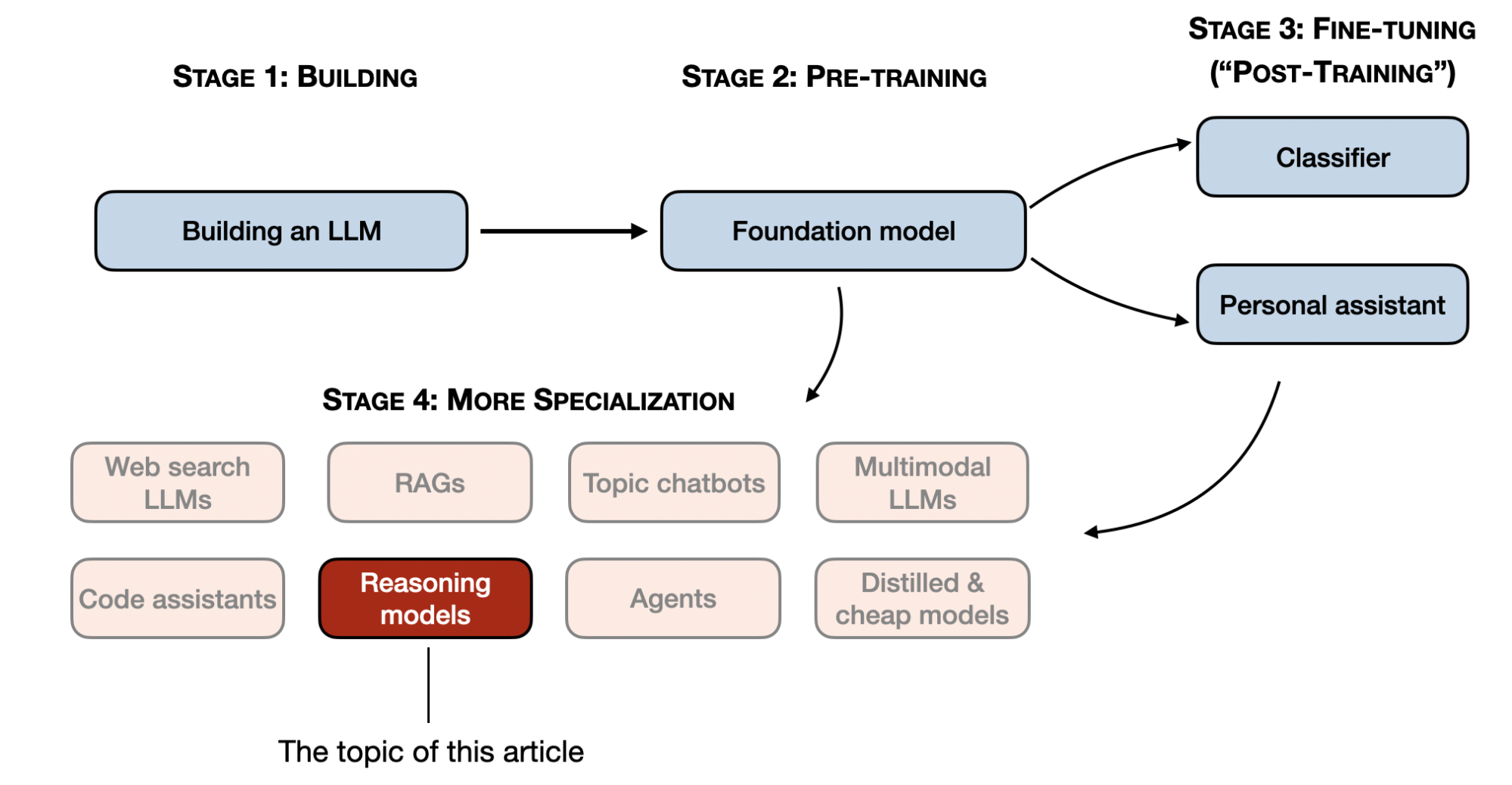
Source: Methods and Strategies for Building and Refining Reasoning Models - Sebastian Raschka
多模态模型则是能够同时处理和整合多种不同类型数据的AI系统。这类模型打破了传统AI只能处理单一类型信息的限制,更接近人类感知世界的方式。
多模态模型可以处理文本、图像、音频、视频等多种模态数据,通过复杂的神经网络架构和学习算法,实现不同模态数据之间的融合与理解。这些模型通过表示学习将不同类型的数据映射到共享的特征空间,再通过对齐和融合技术,建立不同模态之间的联系,最终实现协同推理。
在实际应用中,多模态模型表现出色。例如在视觉问答系统中,模型可以理解图像内容并回答相关问题;在图文生成任务中,能为图像创建准确的文本描述;在多模态情感分析中,综合分析文本、图像等数据的情感倾向;在医疗诊断领域,结合医学影像和病历文本数据提供更准确的诊断建议;在自动驾驶技术中,处理摄像头视觉、激光雷达等多种传感器数据。
多模态模型的优势在于上下文理解更全面,信息获取更丰富,因此准确性往往更高,与用户的交互也更自然。由于利用了多种数据源,这类模型对单一模态中的噪声具有更强的鲁棒性。然而,多模态模型的架构通常更为复杂,需要更多的技术资源,且不同模态数据之间的对齐和融合仍然是技术难点。
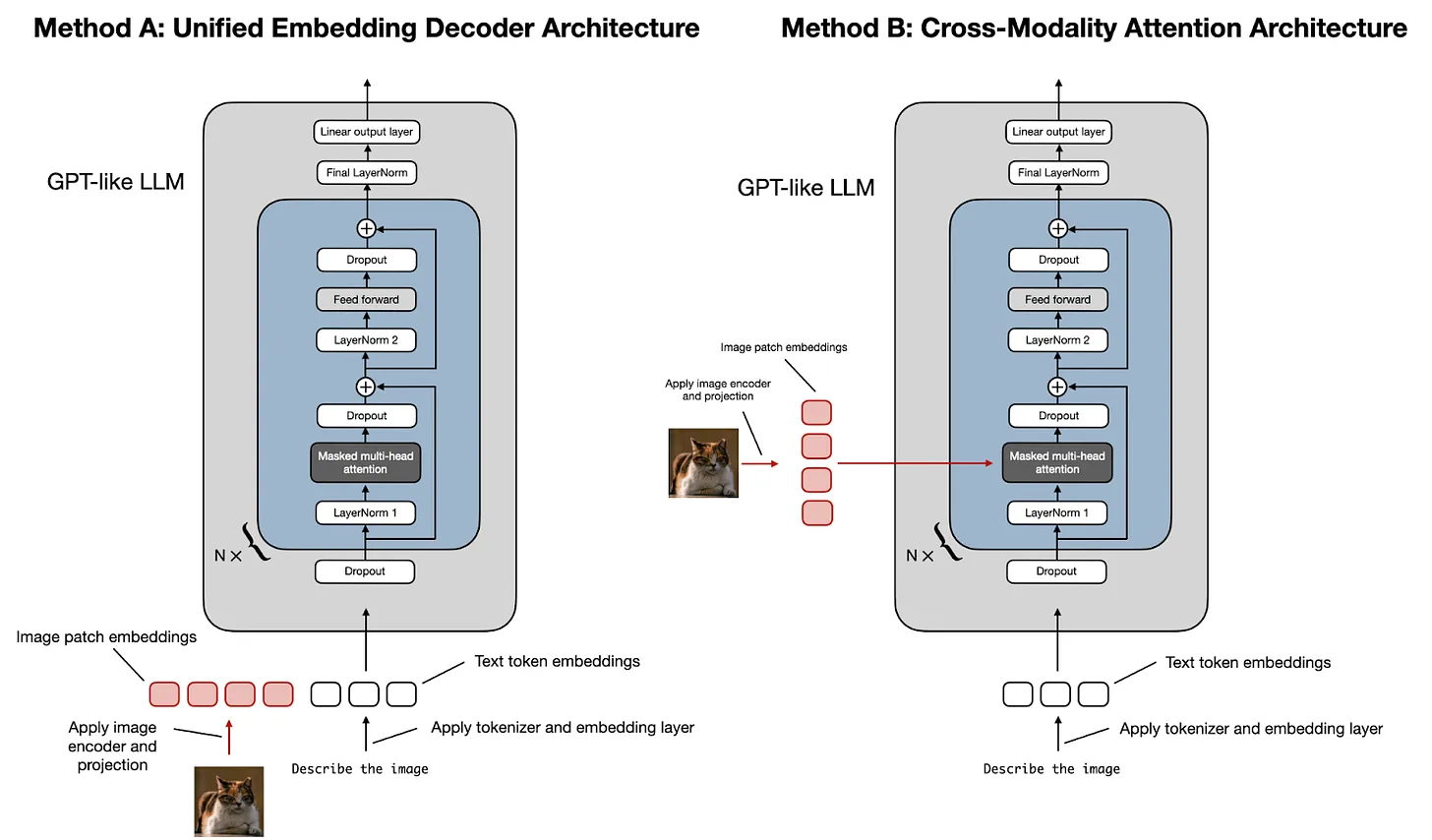
Source: An introduction to the main techniques and latest models - Sebastian Raschka
AI模型的幻觉(hallucination)是指模型生成看似合理但实际上不准确或完全虚构的内容。这个问题在推理模型和多模态模型中都存在,但表现形式和原因有所不同。
推理模型中的幻觉通常表现为逻辑幻觉,即模型生成看似逻辑严密但实际上存在错误的推理过程。例如,在解决数学问题时,模型可能展示一系列看似合理的步骤,但计算结果错误;或者在进行逻辑推理时,使用了错误的前提或推理规则,导致结论偏离事实。
这种幻觉的产生主要源于以下几个原因:首先,推理模型在训练过程中可能接触到的高质量推理示例有限,导致学习到的推理规则不够完备;其次,模型可能过度依赖特定的推理模式而忽略关键细节;最后,复杂推理链中的微小错误可能累积放大,导致最终结果严重偏离正确答案。
为减轻推理模型的幻觉问题,研究人员采用了多种策略,如使用树状或图状结构明确表示推理过程、设计自我验证机制让模型检查中间结果、引入外部工具(如计算器、符号推理系统)辅助验证等。通过让模型思考得更慢更谨慎,幻觉问题可以得到一定程度的缓解。
多模态模型中的幻觉则更为复杂,主要表现为跨模态幻觉,即模型生成的内容与输入的多模态信息不一致。例如,图像描述任务中,模型可能描述了图像中不存在的对象;视觉问答任务中,可能基于对图像的错误理解给出答案;多模态生成任务中,可能创建与文本描述不匹配的图像。
导致多模态幻觉的原因包括:模态间对齐不充分,导致模型无法准确理解不同模态信息之间的对应关系;数据集中的标注偏差或噪声,使模型学习到错误的关联;模型对低频特征的过度泛化;以及不同模态数据之间的信息不平衡,导致模型过度依赖某一模态而忽视其他模态的信息。
针对多模态幻觉问题,研究人员提出了多种解决方案,如改进模态对齐技术、设计更好的跨模态注意力机制、使用对比学习增强模态间语义一致性、引入外部知识库进行事实验证等。此外,通过提高训练数据的质量和多样性,也能在一定程度上减轻幻觉问题。
在幻觉问题上,推理模型和多模态模型有着显著差异。推理模型的幻觉更多体现在逻辑链条和推理步骤上,即使步骤出错,其错误也相对容易通过验证中间结果来发现。多模态模型的幻觉则更为隐蔽,因为跨模态理解本身就存在主观性,模型对多模态信息的错误解读可能更难被直接识别。
从可解释性角度看,推理模型的幻觉相对更易处理,因为其展示了完整的思考过程,便于人类审核;而多模态模型的内部处理机制更为复杂,幻觉的产生原因往往难以追踪。不过,多模态模型通过整合多种信息源,理论上应能减少单一模态信息不足导致的幻觉,但实际上多模态融合的复杂性反而可能引入新的幻觉来源。
在处理数据类型方面,推理模型通常专注于单一类型数据(如文本),通过深入分析单一模态信息进行逻辑推导;而多模态模型则可同时处理多种类型数据,在融合不同信息源的基础上进行理解和决策。
从核心能力看,推理模型擅长逻辑推理和问题解决,侧重思考过程的展示和逻辑链条的构建;多模态模型则擅长跨模态信息整合,提供更全面的场景理解和感知能力。推理模型更像一个善于解决问题的思考者,而多模态模型则更类似于一个全面感知环境的观察者。
技术复杂度上,推理模型的算法逻辑复杂,注重推理链的构建,但架构相对简单;多模态模型则需要更复杂的架构来处理、整合和分析来自多个来源的数据,技术实现难度更高。
在应对幻觉问题上,两类模型各有挑战:推理模型需要确保每一步推理的正确性,容易受到错误逻辑链的影响;多模态模型则需要处理不同模态间的一致性和信息融合问题,面临更复杂的幻觉形式。随着研究的深入,两类模型都在不断改进幻觉检测和纠正机制,以提高其可靠性和实用性。
推理模型和多模态模型代表了AI发展的两个重要方向:一个注重思维过程的透明化和逻辑性,另一个则强调全面感知和多维度理解。这两种模型各有所长,适用于不同的应用场景,也面临不同形式的幻觉挑战。
随着技术的不断进步,这两类模型的能力边界将不断扩展,幻觉问题也将得到更有效的解决。我们已经看到一些研究尝试将推理能力引入多模态模型,或者增强推理模型对多样化数据的处理能力。通过结合两种模型的优势,研究人员希望创建既能进行严谨推理又能全面理解多模态信息的AI系统。
未来,我们可能会看到同时具备强大推理能力和多模态理解能力的混合模型,这将为更复杂的问题提供更全面的解决方案,进一步缩小AI与人类认知能力之间的差距,同时也能更好地防范和减轻AI幻觉问题带来的风险。无论技术如何发展,更好地理解这两类模型的特点、差异及其面临的挑战,将有助于我们更有效地利用人工智能技术解决实际问题。
图片引用源:1.https://magazine.sebastianraschka.com/p/understanding-multimodal-llms
2.https://sebastianraschka.com/blog/2025/understanding-reasoning-llms.html